C 正则表达式
c 正则表达式的一些用法参考
代码¶
my_regex.c 内容如下:
#include <regex.h>
#include <stdio.h>
#include <stdlib.h>
void match_regex_string(const char *pattern, const char *string, int flag)
{
regex_t preg = {0};
int rc;
// 我们的表达式有4个子表达式,所以是5=4(子匹配)+1(全匹配)
size_t nmatch = 5;
regmatch_t pmatch[5];
#define ERROR_MSG_LEN 256
char err_msgbuf[ERROR_MSG_LEN];
if (0 != (rc = regcomp(&preg, pattern, flag)))
{
regerror(rc, &preg, err_msgbuf, ERROR_MSG_LEN);
fprintf(stderr, "正则表达式编译失败, 错误码: %d 错误描述: %s\n", rc, err_msgbuf);
exit(EXIT_FAILURE);
}
else
{
printf("正则表达式编译成功, 找到 [%d] 个子表达式\n", preg.re_nsub);
}
// https://www.gnu.org/software/libc/manual/html_node/Matching-POSIX-Regexps.html
if (0 != (rc = regexec(&preg, string, nmatch, pmatch, 0)))
{
printf("字符串: '%s' 模式: '%s' 匹配失败, 返回值: %d \n", string, pattern, rc);
}
else
{
// https://www.gnu.org/software/libc/manual/html_node/Regexp-Subexpressions.html
printf("全表达式匹配字符串: "
"\"%.*s\" 位置: [%d, %d].\n",
pmatch[0].rm_eo - pmatch[0].rm_so, &string[pmatch[0].rm_so],
pmatch[0].rm_so, pmatch[0].rm_eo - 1);
for (int sub = 1; sub < nmatch; sub++)
{
printf("子表达式字符串(第 [%d] 个括号内): "
"\"%.*s\" 起始位置: [%d] 长度: [%d]\n",
sub,
pmatch[sub].rm_eo - pmatch[sub].rm_so, &string[pmatch[sub].rm_so],
pmatch[sub].rm_so, pmatch[sub].rm_eo - pmatch[sub].rm_so);
}
}
regfree(&preg);
}
int main(void)
{
// char *string = "./mytest() [0x41456c]";
// char *string = "linux-vdso.so.1(__kernel_rt_sigreturn+0) [0xffff92b305b8]";
// char *string = "./lib/somelib.so(+0x50870) [0xffff92860870]";
char *string = "./lib/somelib.so(func_run+0x58) [0xffff9286e1e0]";
// https://en.wikibooks.org/wiki/Regular_Expressions/POSIX-Extended_Regular_Expressions
// 在BRE的规范中 '\(\)' 用于标记子表达式。而c字符串需要对`\`进行转义。 所以在表达式中是`\\(\\)`
// 同理。`?` 也需要转义。
// 在BRE的规范中 `[]` 用于匹配单个字符。 而我们需要匹配`[]`字符,需要转义, 所以在表达式中是`\\[\\]`
char *pattern_bre = "\\(.*\\)(\\(.*\\)+\\?\\(.*\\)) \\[\\(.*\\)\\]";
match_regex_string(pattern_bre, string, 0);
// 在ere的规范中'()' 用于标记子表达式,所以用于标记子表达式的`()`不需要转义,而想要匹配的`(`和`)`字符需要转义。
// 在ere的规范中'+' 用于标记匹配次数,所以用于表达式的`+`不需要转义,而想要匹配的`+`字符需要转义。
char *pattern_ere = "(.*)\\((.*)\\+?(.*)\\) \\[(.*)\\]";
match_regex_string(pattern_ere, string, REG_EXTENDED);
return 0;
}
编译运行¶
gcc my_regex.c
运行结果:
./a.out
正则表达式编译成功, 找到 [4] 个子表达式
全表达式匹配字符串: "./lib/somelib.so(func_run+0x58) [0xffff9286e1e0]" 位置: [0, 47].
子表达式字符串(第 [1] 个括号内): "./lib/somelib.so" 起始位置: [0] 长度: [16]
子表达式字符串(第 [2] 个括号内): "func_run+0x58" 起始位置: [17] 长度: [13]
子表达式字符串(第 [3] 个括号内): "" 起始位置: [30] 长度: [0]
子表达式字符串(第 [4] 个括号内): "0xffff9286e1e0" 起始位置: [33] 长度: [14]
正则表达式编译成功, 找到 [4] 个子表达式
全表达式匹配字符串: "./lib/somelib.so(func_run+0x58) [0xffff9286e1e0]" 位置: [0, 47].
子表达式字符串(第 [1] 个括号内): "./lib/somelib.so" 起始位置: [0] 长度: [16]
子表达式字符串(第 [2] 个括号内): "func_run+0x58" 起始位置: [17] 长度: [13]
子表达式字符串(第 [3] 个括号内): "" 起始位置: [30] 长度: [0]
子表达式字符串(第 [4] 个括号内): "0xffff9286e1e0" 起始位置: [33] 长度: [14]
注意事项¶
regcomp正则表达式的编译很费时间。在实际应用中不要每次都重新编译表达式。regfree与regcomp成对使用。避免内存泄露。err_msgbuf的内容可能超过256 在表达式很长的时候。 实际使用应当根据实际情况设置更大值或者动态申请。可以通过size_t err_size = regerror(rc, &preg, NULL, 0);动态获取错误信息的长度。并且申请资源后重新获取错误信息。nmatch的值与pmatch的大小要跟实际表达式的子表达式(括号内的表达式)的数量匹配。为子表达式的数量+1。 子表达式的数量可以通过编译后的regex_t结构的re_nsub字段获取。注意,动态申请的结构要释放。- 根据匹配结果的下标取匹配串的时候要保证原字符串的存在。
- 根据粗略的测试。
ERE的编译效率比BRE高。而且表达式更容易理解。 - BRE(Base Regular Expressions) 与 ERE(POSIX-Extended Regular Expressions) 的区别可以参考 文档
写正则表达式是个很繁琐的事情。可以利用一些工具进行调试。然后再翻译到对应语言的表达式。
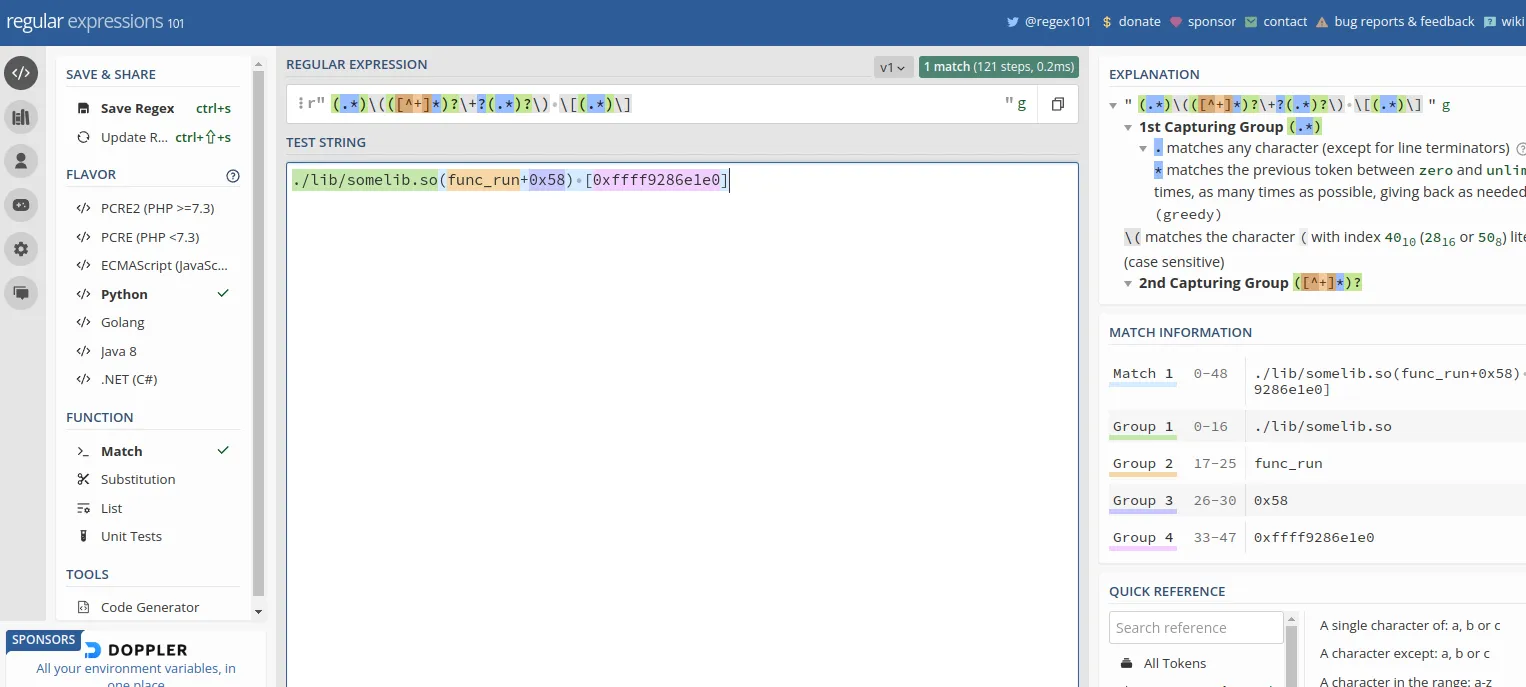
便捷参考¶
内容来自 POSIX-Extended_Regular_Expressions
| 特殊字符 | 说明 |
|---|---|
. | 匹配任何单字符 (许多应用不包含换行, 确切的说哪个字符被看作换行与风格, 字符编码,操作系统等因素相关的[‘\r’,‘\n’,‘\r\n’]. 但是假定包含换行是安全的.). 在 POSIX 中括号表达式内, 点字符匹配字面意义上的点字符 .. 例如: a.c 匹配 “abc”, 但是[a.c] 只匹配 “a”, ”.”, 或者 “c”. |
[ ] | 方括号表达式. 匹配一个在方括号内的字符. 例如: [abc] 匹配 “a”, “b”, 或者 “c”. [a-z] 匹配一个 “a” 与 “z”之间的小写字母. 这些模式可以混合使用: [abcx-z] 匹配 “a”, “b”, “c”, “x”, “y”, 或者 “z”, 跟 [a-cx-z]一样.- 在方括号表达式的开头(在^ 后面) 或结尾的时候看作字面量.例如: [abc-], [-abc]. 注意.不允许反斜杠转义(这里应该指不允许转义[],其他的字符应该是允许的). ] 字符可以出现在方括号表达式的第一个(在 ^之后),例如: []abc]. |
[^ ] | 匹配一个不包含在方括号内的字符. 例如: [^abc] 匹配除了 “a”, “b”, 或者 “c”的任何单个字符. [^a-z] 匹配任何小写”a” 与 “z”之外的单个字符.跟上面一样,字符字面量与范围可以混用. |
^ | 匹配字符串的开头位置. 在基于行的工具中,他匹配任一行的开头位置. |
$ | 匹配字符串的结尾位置或者字符串结尾符之前的位置. 在基于行的工具中,他匹配任一行的结尾位置. |
BRE: \( \)ERE: ( ) | 定义一个被标记的子表达式. 被匹配的字符串可以被重新提起.(参考下一条 _n_). 被标记的表达式也可以叫做block(块)或者capturing group(捕获组). |
_n_ | 匹配 n 次被子表达式匹配的字符, n 是一个1到9 之间的数. 这个构造从理论上就不合理,而且没有被POSIX ERE 语法接受. 一些工具允许匹配超过9次. 不要用这个语法 |
* | 匹配0次或多次前面的元素. 例如: ab*c 匹配 “ac”, “abc”, “abbbc”, 等. [xyz]* 匹配 "", “x”, “y”, “z”, “zx”, “zyx”, “xyzzy”等. \(ab\)* (BRE) 或者 (ab)* (ERE) 匹配 "", “ab”, “abab”, “ababab”等. |
BRE: \+ERE: + | 匹配1次或多次前面的元素. 例如: ab\+c (BRE) 或者 ab+c (ERE) 匹配 “abc”, “abbbc”, 等, 而不是 “ac”. [xyz]\+ (BRE) 或者 [xyz]+ (ERE) 匹配 “x”, “y”, “z”, “zx”, “zyx”, “xyzzy”等. \(ab\)\+ (BRE) 或者 (ab)+ (ERE) 匹配 “ab”, “abab”, “ababab”等. |
BRE: \?ERE: ? | 匹配0次或 1次前面的元素. 例如: ab\?c (BRE) 或者 ab?c (ERE) 匹配 “ac” 和 “abc”, \(ab\)\? (BRE) 或者 (ab)? (ERE) 匹配 "" or “ab”. |
| BRE: \| ERE: | | 匹配前面或者后面的元素. 例如: abc|def (BRE) 或者 abc|def (ERE) 匹配 “abc” 和 “def”. |
BRE: \{_m_,_n_\}ERE: {_m_,_n_} | 匹配前面的元素至少m次,不多于n次. 例如: a\{3,5\} (BRE) or a{3,5} (ERE) 只匹配 “aaa”, “aaaa”, 与 “aaaaa”. |
BRE: \{_m_\}ERE: {_m_} | 恰好匹配前面的元素m次. |
BRE: \{_m_,\}ERE: {_m_,} | 匹配前面的元素至少m次. |
BRE: \{,_n_\}ERE: {,_n_} | 匹配前面的元素不多于n次. 例如: ba\{,2\}b (BRE) or ba{,2}b (ERE) 只匹配 “bb”, “bab”, 与 “baab”. |
便捷表达¶
| POSIX class | similar to | meaning |
|---|---|---|
| [:upper:] | [A-Z] | 大写字母 |
| [:lower:] | [a-z] | 小写字母 |
| [:alpha:] | [[:upper:][:lower:]] | 大写字母 和 小写字母 |
| [:alnum:] | [[:alpha:][:digit:]] | 数字,大写字母 和 小写字母 |
| [:digit:] | [0-9] | 数字 |
| [:xdigit:] | [0-9A-Fa-f] | 16进制字母 |
| [:punct:] | [.,!?:…] | 标点符号 |
| [:blank:] | [ \t] | 空格和TAB |
| [:space:] | [ \t\n\r\f\v] | 空白字符 |
| [:cntrl:] | 控制字符 | |
| [:graph:] | [^\t\n\r\f\v] | 可打印字符 |
| [:print:] | [^ \t\n\r\f\v] | 可打印字符和空格 |
参考¶
在 *unix 系统中, 可以通过 man regcomp 等命令参考系统自带的文档。
这篇怎么样?