编译期内存序
nxdong August 28, 2022 [linux] #翻译翻译编译器内存序。 memory-ordering-at-compile-time/
翻译自:memory-ordering-at-compile-time/
编译期内存序
memory-ordering-at-compile-time
从写下代码的时候到运行在cpu上,这些代码对应的内存交互可能会在一些规则下重新排列。
内存序的改变由编译器(编译时)和处理器(运行时)共同完成,这些都是为了提高代码的运行速度.
编译器开发者与cpu厂商共同遵循的内存重拍规则大概可以这样概述:
Thou shalt not modify the behavior of a single-threaded program.(不改变单线程程序的行为).
由于这个规则,程序员在写单线程程序的时候绝大部分情况下可以忽略内存指令重排. 很多时候在多线程程序中也可以忽略内存重排, 因为mutexes,semaphores,events在设计之初就避免了调用处的指令重排.只有在使用无锁技术(内存在多个线程共享,但是没有额外的交互)编程这个特例情景中,才可以观察到内存重排的副作用.
为多核平台写无锁程序而不受内存重排的影响是可能的. 你可以选择顺序一致性的类型.比如 java里的volatile变量,或者c++11的atomics(可能需要一点点性能的代价).
接下来会重点关注编译器在一般情况下对非顺序一致性类型的内存重排.
编译器指令重排
众所周知,编译器的工作就是把人类可读的代码转换成机器(CPU)可读的编码.在这个转换过程中,编译器有很大的自由度.
其中一个自由就是指令重排 ( 在不影响单线程程序表现的情况下 ). 指令重排一般只在开启优化的时候发生.
例如如下函数:
int A, B;
void
无优化编译到汇编:
# 内容如下
## %bb.0:
## -- End function
gcc:
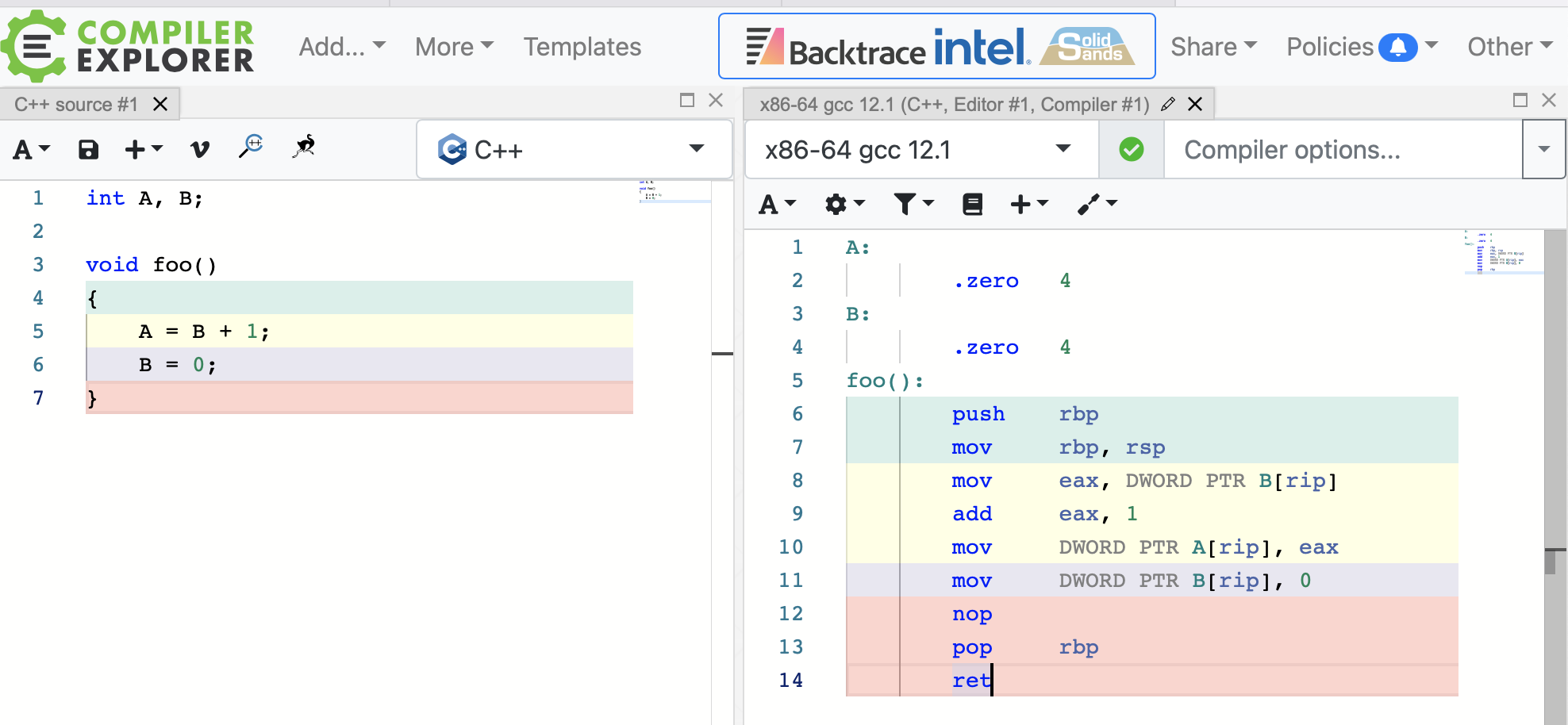
带-O2汇编
## %bb.0:
## -- End function
gcc:
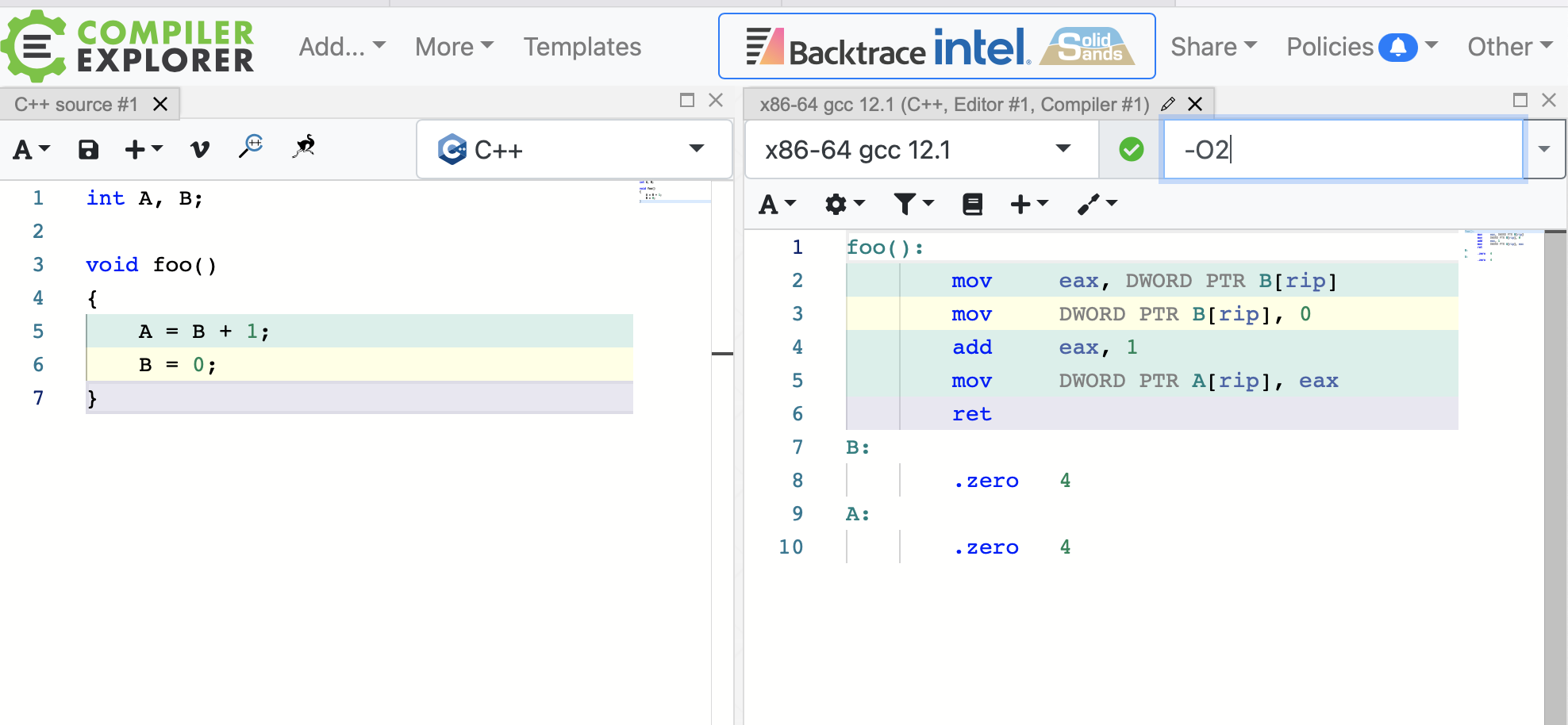
这时,编译器重排了写入的顺序,把写入B调整到了写入A之前。单线程的表现没有改变。
另一方面,这样的重排会在无锁编程的时候带来很多问题。
下面是个常用的例子,一个用于标记共享值是否发生改变的共享标记。
int Value;
int IsPublished = 0;
void
想象这样一个场景,编译器重排把 IsPublished 的赋值操作放到Value的赋值之后。
即使在单处理器系统中,我们也有一个问题:一个线程可能在两个赋值操作中间被操作系统中止,但是别的线程认为Value已经更新了,但是并没有。
当然啦,编译器也可能不重排这些操作,并且机器码也会在有强内存模型的多核cpu(x86/64或者单处理器环境)中运行无锁操作很好。在这种情况下,我们应该认为是幸运的。无须多言,更好的实践是认识到内存重排在不同共享变量上的可能性,并且强制保证正确的顺序。
显式编译器屏障
防止编译器重排的最简单的办法就是使用一个叫编译器屏障的命令。
下面是一个完整的编译器屏障。在微软的Visual C++中,使用_ReadWriteBarrier.
int A, B;
void
做了这些改动,我们就可以开启优化选项,并且内存存储会保持我们想要的顺序。
# clang -masm=intel foo.c -S -o foo.s -O2
# clang编译没有观察到代码生效。 上面的代码写法是GCC的写法
gcc 如下:
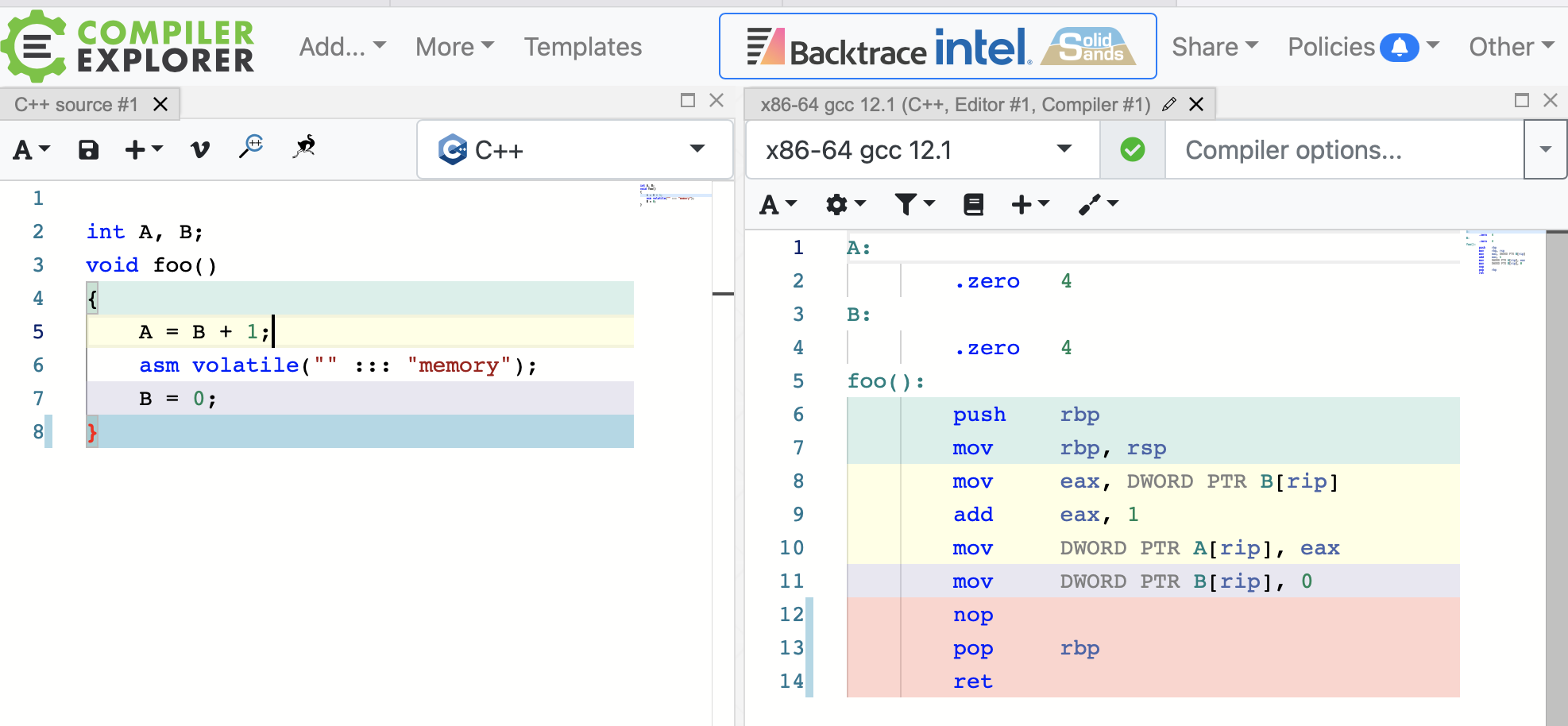
同理,如果我们想让sendMessage 示例正常工作,并且我们只关心单处理器系统,最小变化,我们需要在这里引入编译器屏障. 不仅发送操作需要一个编译器屏障来避免存储重排,而且接收操作也需要在加载内存的时候加上编译器屏障.
int Value;
int IsPublished = 0;
void
int
就像我提到的,编译器屏障足够保证避免单处理器系统的内存重排. 但是现在多核处理器是常态.如果我们想在多核处理器上保证交互按我们想要的顺序进行,而且在任何cpu架构上都有效, 只有编译器屏障是不够的.我们也需要引入CPU栅栏操作,或者在运行时执行任何作为内存屏障的操作. 更多信息参考Memory Barriers Are Like Source Control Operations
Linux 内核通过预处理宏(比如 smb_rmb)暴露了几个CPU栅栏指令,而且这些宏会在编译到单核系统的时候退化成简单的编译器屏障.
隐式编译器屏障
也有其他的方便避免编译器重排. 实际上,之前提到的CPU栅栏指令也能当编译器屏障.
下面是一个PowerPC的CPU栅栏指令的GCC宏:
无论我们在代码的什么地方插入RELEASE_FENCE ,它会避免除了编译器重排之外的几个类型的处理器重排.
举个例子,它可以使sendValue在多核系统中安全:
void
在 C++11 的原子基础库标准中,每一个 non-relaxed 原子操作也表现为编译器屏障.
int Value;
std::atomic<int> ;
void
而且,如你所想, 每一个包含编译器屏障的函数自己也表现为编译器屏障.甚至这个函数是个inline 函数.(然而,微软文档(Microsoft’s documentation)说在早期的VC++ 版本中并不是这样.)
void
实际上,大部分函数调用可以当做编译器屏障,不管它们是否包含它们自己的编译器屏障. 排除inline 函数 与声明了 pure 属性的函数(pure attribute 和开启了链接时代码生成的情况. 除了这些情况,调用一个外部函数甚至比编译器屏障还强,因为编译器不知道函数的副作用是啥. 它必须放弃所有关于函数可见内存的假设.
仔细想想,这完全说得通.在上面的代码片段中,假设sendValue 的实现在另外的库里. 编译器怎么知道 sendValue 不依赖 foo->bar 的值呢? 怎么知道sendValue 不会修改foo->bar 的内存呢? 它不知道. 因此为了遵循内存重排的基本规则,它不能重排sendValue 这个外部调用附近的任何内存操作.同样的,它也必须在调用完成后重新在内存获取foo->bar 的值,而不是假定它是5,即使开了优化.
$ gcc -O2 -S -masm=intel dosomestuff.c
$ cat dosomestuff.s
...
mov ebx, DWORD PTR
mov DWORD PTR , 5 // Store 5 to foo->bar
mov DWORD PTR , 123
call sendValue // Call sendValue
mov eax, DWORD PTR // Load fresh value from foo->bar
mov DWORD PTR , eax
...
如你所见, 在很多情况下内存重排是禁止的, 甚至编译器必须从内存重新加载值.
我认为这些隐藏规则在很大程度上解释了为什么volatile类型在c 多线程编程中是不必要的. not usually necessary in correctly-written multithreaded code.
Out-Of-Thin-Air Stores
在C++11被标准化之前,从技术上讲,没有任何规则阻止编译器达到更糟糕的技巧。特别是,编译器可以自由地将存储引入共享内存,而以前没有存储。这是一个非常简化的例子,灵感来自Hans Boehm在多篇文章中提供的例子。
int A, B;
void
虽然这在实践中不太可能,但没有什么能阻止编译器在检查A之前将B提升到寄存器,从而产生等效于以下内容的机器代码:
void
再一次,内存排序仍然被遵循基本规则。单线程应用程序不会更好。但是在多线程环境中,我们现在有一个可以清除其他线程中同时对 B 所做的任何更改(即使 A 为 0 )的函数。原始代码没有这样做。这种晦涩难懂、技术上不可能性是人们一直说C++不支持线程的部分原因,尽管几十年来我们一直乐于用C/C++编写多线程和无锁的代码。
我不知道有谁在实践中成为这种Out-Of-Thin-Air Stores的受害者。也许只是因为对于我们倾向于编写的无锁代码类型,没有太多适合这种模式的优化机会。我想如果我发现这种类型的编译器转换发生,我会寻找一种方法来使编译器陷入困境。如果它发生在你身上,请在评论中告诉我。
在任何情况下,新的C++11标准明确禁止编译器在引入数据竞争的情况下进行此类行为。该措辞可以在最近的C++11工作草案的§1.10.22中找到:
此标准通常排除了将赋值引入到抽象机器不会修改的潜在共享内存位置的编译器转换。
为什么编译器重新排序?
正如我在开始时提到的,编译器修改内存交互的顺序与处理器修改的原因相同 - 性能优化。这种优化是现代CPU复杂性的直接结果。
参考
https://preshing.com/20120625/memory-ordering-at-compile-time/